
Les Modèles SVM une introduction dans leurs utilisations dans le trading

Un des avantages indéniables des régressions logistiques réside dans leur simplicité et leur efficacité à modéliser des relations linéaires entre les variables. Toutefois, le monde réel est peuplé de dynamiques bien plus complexes, souvent non linéaires, qui dépassent les capacités des modèles linéaires classiques. Face à cette réalité, il devient impératif d'explorer des algorithmes plus sophistiqués capables de capter ces subtilités. C'est dans cette optique que je vous propose de découvrir un algorithme polyvalent non seulement applicable à la classification mais aussi à la régression : la Machine à Vecteurs de Support (SVM).
En outre, nous explorerons une technique révolutionnaire, connue sous le nom de kernel trick, qui permet d'embrasser la complexité des relations non linéaires. Cette méthode enrichit significativement notre modèle, lui permettant de s'adapter à presque toutes les configurations de données, qu'elles soient linéaires ou non linéaires.
Pour illustrer l'efficacité des SVM et du kernel trick, je vous guiderai à travers une étude de cas concrète où nous appliquerons ces outils à la prédiction des mouvements de marché. Nous détaillerons les étapes de la mise en œuvre d'un modèle SVM pour analyser et prédire les tendances futures basées sur des données historiques. Ce cas pratique mettra en lumière non seulement la théorie mais aussi l'application pratique des SVM en trading.
Le but de cet article est de se concentrer davantage sur la pratique, même si je vais rapidement passer sur les équations importantes. Pour ceux qui souhaitent approfondir la théorie, je vous conseille cette vidéo de la chaîne AIforyou : lien YouTube.
L'idée fondamentale d'un modèle SVM est de trouver l'hyperplan qui sépare nos classes en deux, tout en maximisant la marge entre cet hyperplan et les vecteurs de support. Les vecteurs de support, quant à eux, correspondent aux points les plus proches de notre hyperplan, influençant directement sa position et son orientation pour optimiser la séparation des classes. Voici une illustration pour mieux comprendre. Dans le contexte financier, les deux classes représentées par les couleurs bleue et verte peuvent respectivement indiquer une tendance haussière et baissière.
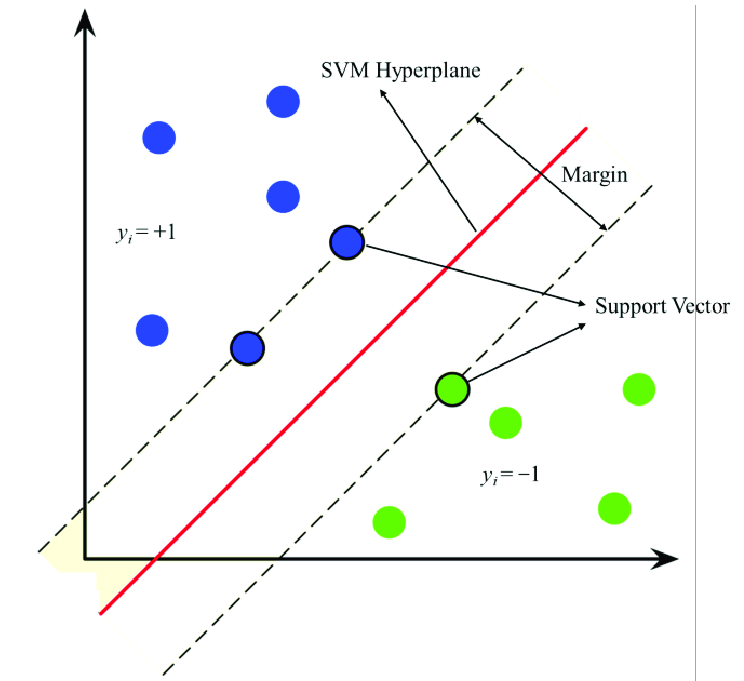
Pour trouver l'hyperplan qui divise parfaitement nos données, nous devons utiliser cette fonction de coût en faisant varier nos paramètres :
Pour un SVM linéaire (sans kernel) :
La fonction de coût dans le SVM linéaire combine un terme de marge avec un terme de régularisation. Elle peut être formulée de la manière suivante :
Pour mieux comprendre le kernel trick et son rôle essentiel dans la transformation des machines à vecteurs de support (SVM) pour la gestion de relations non linéaires, nous devons d'abord explorer ce que cela implique de manière plus intuitive et accessible.
Le Concept de Base
Dans sa forme de base, une SVM classifie les données en trouvant l'hyperplan le plus optimal qui sépare les différentes classes. Cependant, cela fonctionne bien seulement quand les données sont linéairement séparables, c'est-à-dire qu'on peut les diviser avec une ligne droite (dans deux dimensions) ou un plan (dans trois dimensions). Mais que faire si les données ne sont pas linéairement séparables ?
Introduction au Kernel Trick
C'est ici qu'intervient le kernel trick, une méthode ingénieuse qui permet à l'SVM de traiter efficacement des cas où les relations entre les données sont complexes et non linéaires. Le kernel trick transforme les données initiales, qui peuvent être intriquées et entremêlées dans leur espace d'origine, en les projetant dans un nouvel espace de dimensions plus élevées où elles deviennent linéairement séparables. Voici un exemple où nous tentons de séparer deux classes représentées par des points bleus et rouges :
Fonctionnement du Kernel Trick
Imaginez que vous avez des données disposées en cercle dans un plan bidimensionnel. Linéairement, il est impossible de les séparer simplement avec une ligne. Le kernel trick nous permet de projeter ces données dans une troisième dimension, peut-être en les élevant à une certaine puissance ou en utilisant d'autres transformations mathématiques complexes. Soudain, ce qui semblait enchevêtré devient clair et distinct lorsque vu de cette nouvelle perspective, permettant à une SVM de tracer un hyperplan séparateur.
Utilisation des Landmarks
Une façon de conceptualiser ce processus est d'utiliser ce qu'on appelle des "landmarks". Un landmark est un point de référence placé dans l'espace de caractéristiques. Pour chaque point de donnée, nous calculons sa distance par rapport au landmark. Cette distance, souvent transformée par une fonction de kernel comme la RBF (Radial Basis Function), devient une nouvelle caractéristique des données.
Par exemple, si nous utilisons la fonction RBF, la caractéristique calculée pourrait exprimer la "proximité" de chaque point de donnée au landmark selon une mesure exponentielle de leur distance euclidienne. Plus un point est proche du landmark, plus sa nouvelle caractéristique aura une grande valeur.
Mathématiquement, l'utilisation de la fonction de kernel RBF pour transformer les données se décrit par :
où γ est un paramètre de la fonction de kernel qui contrôle l'étendue de l'influence des landmarks.
En plus de la RBF, d'autres fonctions kernel peuvent être utilisées, chacune ayant des propriétés uniques :
Répétition et Expansion de l'Espace de Caractéristiques
En plaçant plusieurs landmarks à différentes positions stratégiques dans les données (ces positions peuvent être choisies de manière aléatoire ou basée sur des critères spécifiques), et en répétant le processus de transformation, nous enrichissons l'espace des caractéristiques. Cela permet de construire un nouvel espace où les relations non linéaires dans les données originales deviennent visibles et gérables pour une SVM linéaire.
Conclusion
"""
Pipeline d’analyse de données et de classification SVM.
Dépendances :
• pandas – manipulation et analyse de données
• numpy – calcul scientifique (tableaux, opérateurs vectoriels)
• requests / aiohttp / asyncio
– requêtes HTTP synchrones et asynchrones
• yfinance – récupération de données financières historiques
• xicorrelation.xicorr
– calcul de dépendances non linéaires
• scipy.stats.pearsonr
– coefficient de corrélation de Pearson
• scikit-learn – apprentissage automatique (SVC, RobustScaler)
• matplotlib.pyplot – visualisations
• tqdm – barres de progression
"""
# ——————— Imports standard ———————
import os
import asyncio
# ——————— Imports HTTP ———————
import requests
import aiohttp
import yfinance as yf
# ——————— Imports calcul scientifique ———————
import numpy as np
import pandas as pd
from scipy.stats import pearsonr
from xicorrelation import xicorr
# ——————— Imports machine learning ———————
from sklearn.preprocessing import RobustScaler
from sklearn.svm import SVC
# ——————— Imports visualisation & utilitaires ———————
import matplotlib.pyplot as plt
from tqdm import tqdmLe kernel trick est donc un outil puissant qui transforme un modèle simple, initialement conçu pour détecter des relations linéaires, en un modèle capable de démêler et de classifier des relations bien plus complexes. Cette transformation ne nécessite pas de calculs de dimensions supérieures explicitement, rendant les SVM non seulement très efficaces mais aussi extrêmement puissantes pour des tâches de classification complexes.
Le but est de construire un dataset. Notre cible est la tendance future sur 10 jours et les caractéristiques seront un indicateur de sentiment calculé à partir des actualités et diverses transformations du prix et du volume de transactions, telles que les log-returns avec diverses retards ou le volume en dollars et autres.
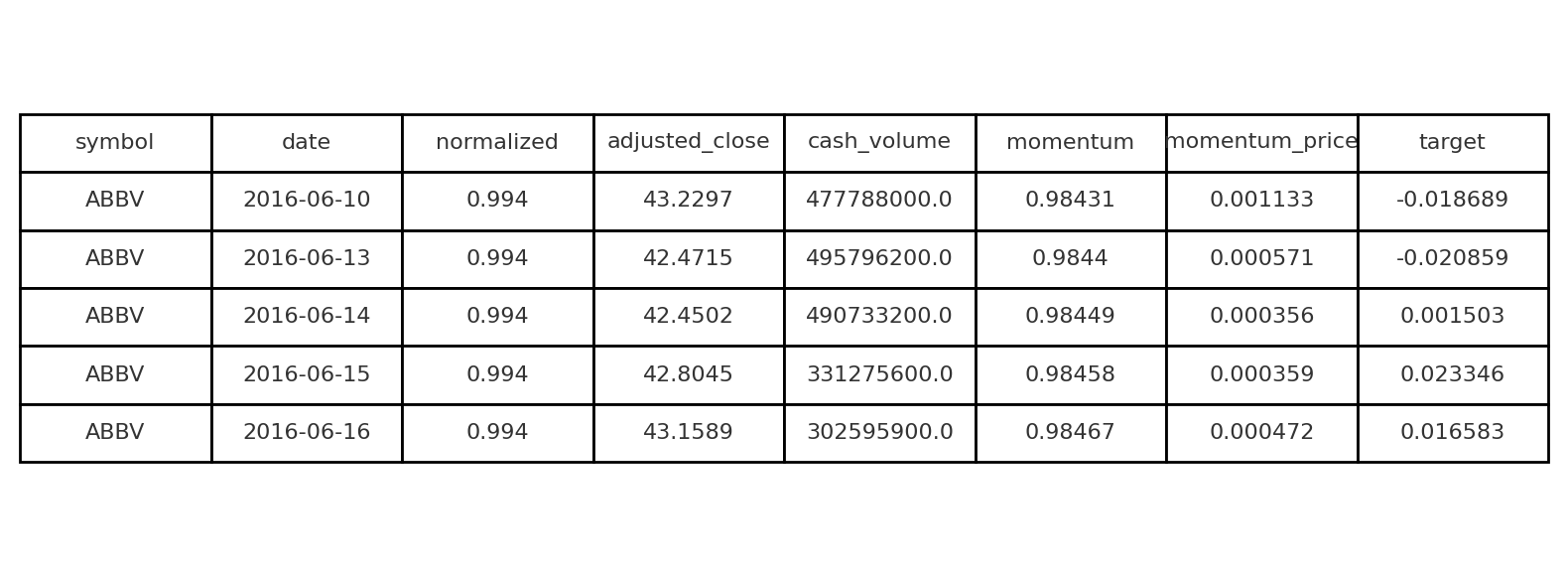
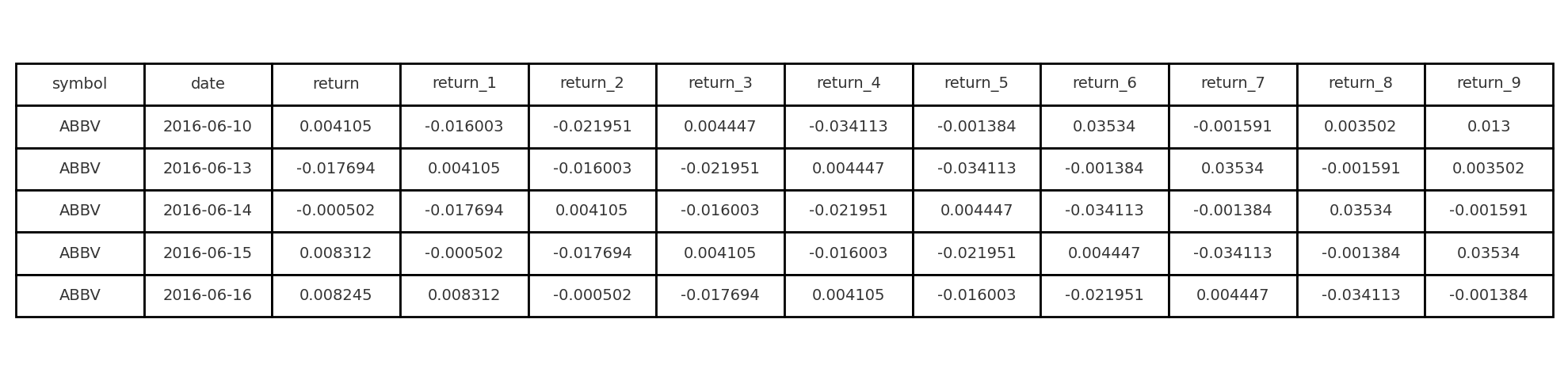
Maintenant qu'on a un dataset, la première étape est de séparer nos datasets en jeux de test et d'entraînement :
# Définir la date de séparation
cutoff = '2017-12-31'
# Extraire la série de dates
dates = all_data.index.get_level_values('date')
# Construire train et test sets
train_set = all_data[dates <= cutoff].dropna()
test_set = all_data[dates >= cutoff].dropna()La deuxième étape est d'entraîner notre modèle, mais avant, il faut normaliser nos données. Je vous conseille d'utiliser RobustScaler, qui est moins sensible aux valeurs aberrantes. Ensuite, il faut encoder notre cible : 1 pour une tendance haussière et 0 pour une tendance baissière.
# Importation de RobustScaler pour normaliser avec robustesse
scaler = RobustScaler()
# Normalisation des features (exclut 'target') et conservation des index/colonnes
X_train = pd.DataFrame(
scaler.fit_transform(train_set.drop('target', axis=1)),
index=train_set.index,
columns=train_set.columns.drop('target')
)
# Création de y_train : 1 si target > 0, sinon 0
y_train = np.where(train_set['target'] > 0, 1, 0)
# Initialisation et entraînement du SVM (kernel RBF, proba activées)
model = SVC(kernel='rbf', probability=True)
model.fit(X_train, y_train)La dernière partie consiste à faire les prédictions et à analyser les résultats :
# Normalisation des features de test (exclut 'target' et 'adjusted_close')
X_test = pd.DataFrame(
scaler.transform(
test_set.drop(['target', 'adjusted_close'], axis=1)
),
index=test_set.index,
columns=test_set.columns.drop(['target', 'adjusted_close'])
)
# Prédiction des probabilités de chaque classe
preds = model.predict_proba(X_test)
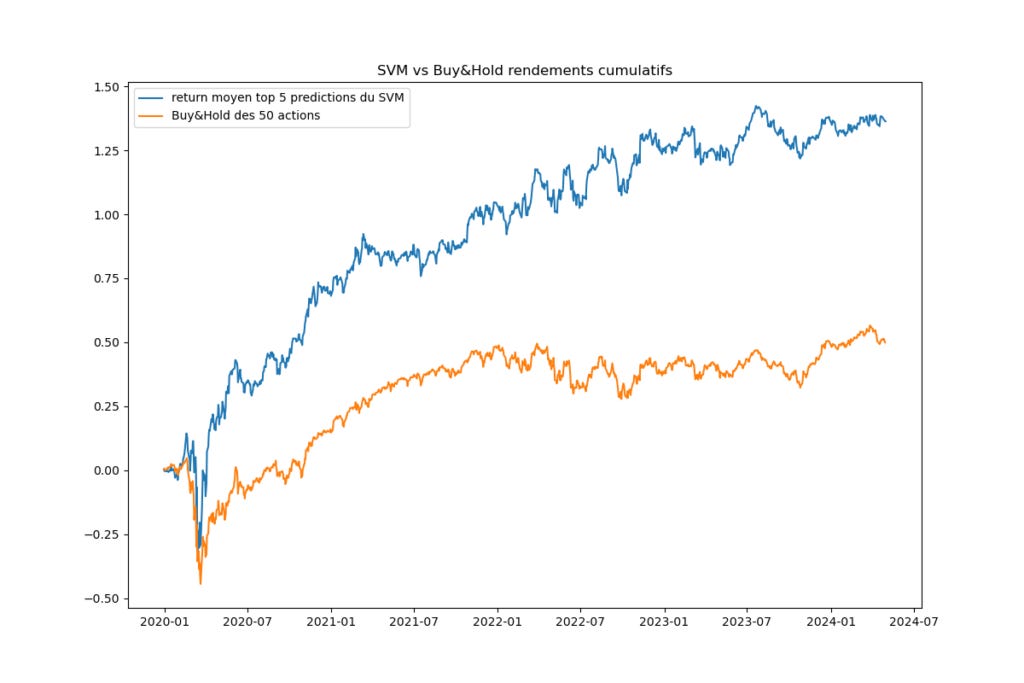
On voit qu'il pourrait y avoir un avantage à utiliser les prédictions du modèle pour prendre des décisions d'investissement. Je vous conseille de faire vos propres recherches avec les modèles SVM pour voir ce qui vous convient ou non et approfondir le raisonnement vu précédemment.